
Published on
Addepar’s scale
Addepar was founded in 2009 based on a simple, yet powerful idea: to maximize the positive impact of the world's capital. Translating this mission into reality requires a platform capable of handling immense complexity. Currently, the platform supports nearly $9 trillion in assets, storing 100 billion financial account snapshots and 10 billion transaction records on over hundreds of millions of positions. The platform executes over 10 million calculations per day. These numbers are expected to keep increasing as the company expands over the coming years.
At this volume, data management strategies that work for smaller datasets become significant operational bottlenecks. Routine maintenance operations such as adding client data or migrating a firm to a different region may require processing billions of rows. During normal operation, the lock contention, noisy neighbor issues and other problems can quickly become overwhelming.
To address these challenges, Addepar introduces multi-schema database partitioning. Instead of managing data in shared tables, the architecture encapsulates each client in their own identical, self-contained database schema. This approach delivers significant advantages in operational flexibility, performance and security, and simplifies the implementation of some new products.
Data architecture and its advantages
In the architecture based on schema partitioning, all data belonging to a specific client is stored in the client’s individual schema. This includes all financial information, reports generated by the platform, financial documents, personalization settings, etc.
For data sets that do not belong to a specific client, Addepar uses two storage approaches. Complex data sets such as market data (security identifiers, market cap, 52-week maximum) and financial benchmarks are maintained in dedicated services. These are only referenced within client schemas via global IDs. Low cardinality data is denormalized and replicated within client schemas to reduce lookup overhead. The simplicity of this approach justifies the minimal storage overhead that comes with it. See an example in the pseudocode below.
Note that we cannot simply store the auxiliary complex datasets alongside client schemas and perform joins on them via foreign keys; they would become invalid if a client schema were to be relocated to a different region and/or instance.
-- An example of a client-specific table inside a client schema
-- transaction_type_id: references a denormalized table
-- security_id: references an external service
-- client_id field has the same value in all rows of this
-- client schema
mysql> select * from transaction limit 3;
+----+-----------+---------------------+-------------+
| id | client_id | transaction_type_id | security_id |
+----+-----------+---------------------+-------------+
| 1 | 3 | 10 | 5007 |
| 2 | 3 | 10 | 5008 |
| 3 | 3 | 20 | 5009 |
+----+-----------+---------------------+-------------+
-- A client-agnostic table inside a client schema.
-- References from client-specific tables
-- (e.g., the `transaction_type_id` column in the `transaction`
-- table) can be resolved via a simple JOIN
-- client_id field has the same value in all rows of this
-- client schema
mysql> select * from transaction_type where id in (10, 20);
+----+-----------+----------+
| id | client_id | type_str |
+----+-----------+----------+
| 10 | 3 | BUY |
| 20 | 3 | SELL |
+----+-----------+----------+
-- Data hosted on an external service
-- References from client-specific table (e.g.,the `ticker_symbol_id` column -- in the `transaction` table) must be resolved via an external service call
-- (Only relevant rows shown)
mysql> select * from security where id in (5007, 5008, 5009);
+------+------+--------+--------+
| id | name | bid | ask |
+------+------+--------+--------+
| 5007 | GOOG | 287.43 | 312.53 |
| 5008 | META | 653.55 | 654.56 |
| 5009 | GM | 82.4 | 82.5 |
+------+------+--------+--------+
Client specific tables hold references to common data. Depending on the complexity, the common data set is hosted inside the client schema(s) or on an external server.
Operational advantages
With isolated per-client schemas, Addepar can treat entire schemas as first-class citizens for certain operational procedures. For example, as a client’s requirements evolve and they outgrow the infrastructure they’re hosted on, we can easily migrate them into a more powerful machine by simply relocating the entire schema. This capability also facilitates “lift and shift” of the entire data set into a different geographic region, should the client require it. In either case, the only component requiring a physical migration is the client schema itself, as the client-agnostic data is hosted on globally-accessible servers and is not affected by client data movement.
The architecture’s strict encapsulation also provides the ability to manage isolated environments. We can avoid complex filtering logic and use the database’s native schema operations to:
Create full clones of client environments, allowing them to test-drive their changes before rolling them out to their entire customer base.
Refresh the environment clones with updated datasets to match the client’s current production state when needed.
Provision isolated demo instances to help showcase the platform to prospects and run training camps.
Accelerate QA efforts by generating fast and cost-effective copies of synthetic test datasets to fuel internal development.
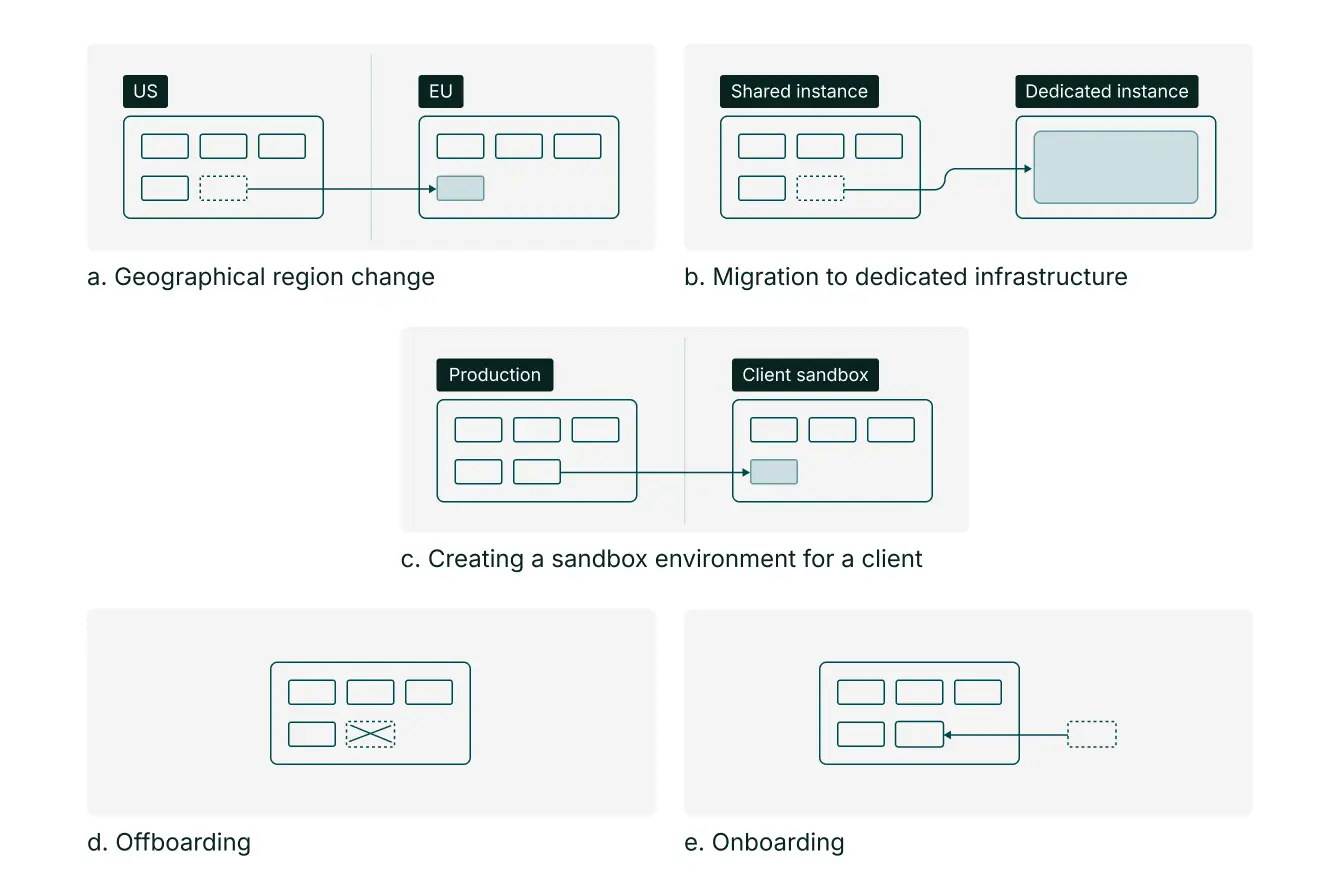
Overview of operations made simple by client data encapsulation (small rectangles represent client schemas)
Onboarding a major new client requires significant data operations, often requiring the ingestion of 15 years or more of financial history. This process involves loading potentially hundreds of millions of rows and expanding data sets by an order of magnitude overnight. In this architecture, these heavy write operations are encapsulated within the client’s environment; transactional queries that might otherwise result in instance-wide locks are limited solely to the specific client being onboarded. This allows the platform to ingest large volumes of data without risking deadlocks or degrading performance for other clients sharing the infrastructure.
Performance advantages
Because data is partitioned, transactional queries that require database locks are strictly scoped to a single client’s schema. This ensures that a high-volume or complex operation running for one client — such as a massive reporting job — cannot trigger instance-wide locks. Consequently, the "noisy neighbor" effect is greatly diminished.
Additionally, we can configure each client schema with the collation rules specific to that client's region and language, such as Turkish or Japanese. This design leverages the database engine’s ability to perform sorting natively at the source instead of during the retrieval, making certain queries more efficient.
Security and safety
The isolated schema architecture enhances platform resilience by enabling targeted disaster recovery. Because each client's dataset is fully encapsulated within its own schema, we can leverage built-in database tools to restore a single client to a past state without impacting the rest of the platform or other clients. This granular control allows us, should a need arise, to surgically revert a specific client’s environment without the possibility of affecting other customers.
Security can be reinforced by access control measures enforced directly at the database schema layer. We can assign permissions strictly on a per-schema basis, ensuring that operational teams and automated processes are granted access to only the specific client datasets they are authorized to manage. This also simplifies implementation of cross-region isolation required by certain jurisdictions.
Data architecture consequences
Platform design
The decision to isolate client data dictates specific requirements for the platform's service architecture. Because client-agnostic data (such as market data) is extracted into separate services, the platform now requires responses from both the client’s core database schema and these services in order to respond to user queries. We protect the platform from outsized impact of failures in these services by implementing caches aimed at providing graceful degradation. An additional benefit from using these caches is improved query performance.
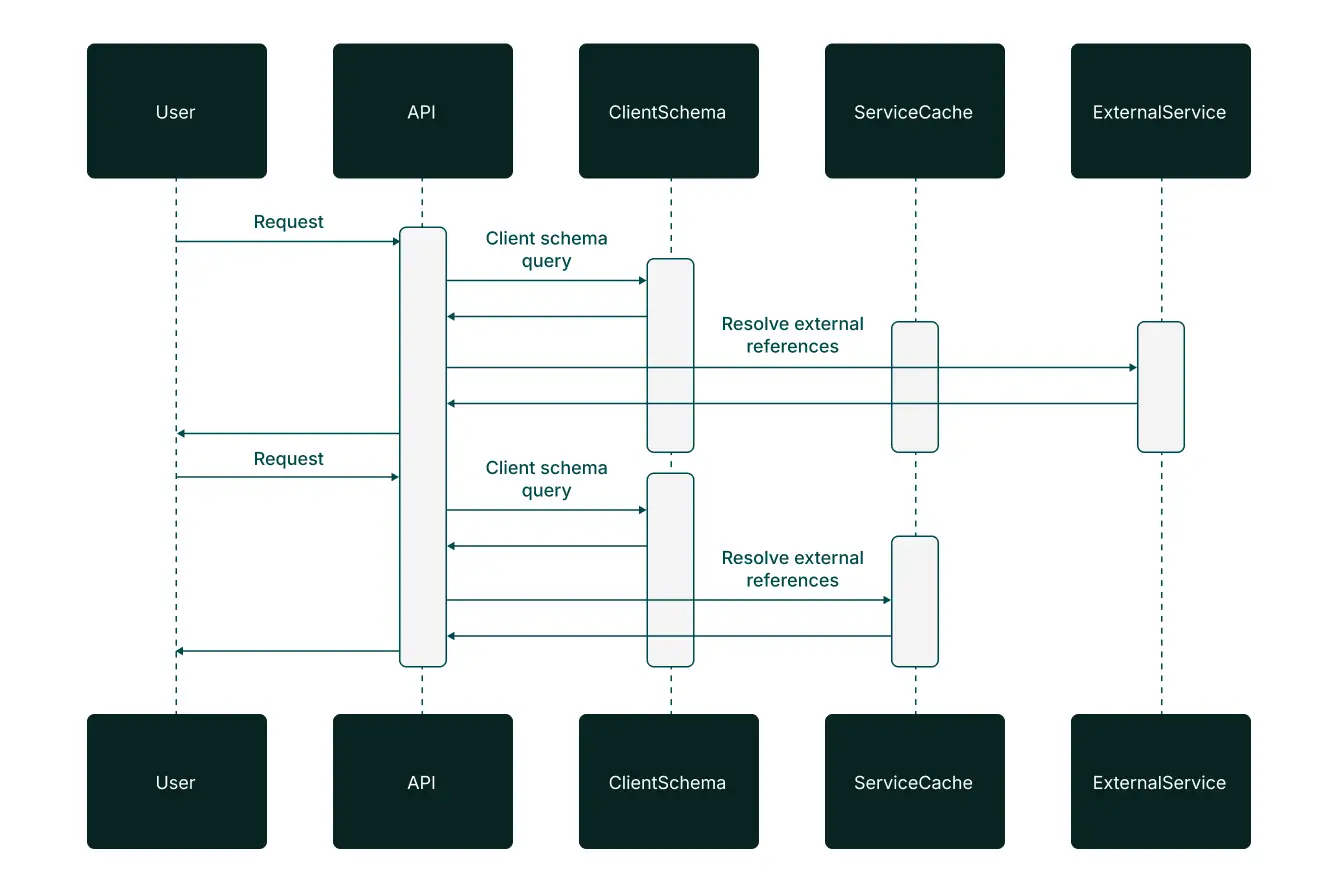
References to client-agnostic data hosted outside of the client schema cannot be resolved by database JOINs and are handled separately in the application layer. Caching ensures graceful degradation.
An interesting note is that in this architecture, any application cache that fronts a database table needs to be indexed by both the table’s primary key and the schema ID, as the primary key by itself is not guaranteed to be unique.
Runtime implications
To bridge the application layer with the partitioned data model, we made extensions to two database libraries we use heavily: Flyway for database migrations, and JOOQ for database querying.
Addepar’s Flyway migrations are explicitly categorized by scope — labeled as either 'client-specific' or 'client-agnostic' — which dictates their execution target. The system uses these labels to automatically broadcast and apply 'client-specific' migration files to all client schemas simultaneously. The client-agnostic migrations are applied to only a common schema containing ephemeral datasets, such as instance caches.
During runtime, the platform utilizes a specialized execution hook written for the JOOQ request library. This hook functions as a router for database interactions; it dynamically analyzes the WHERE clause of queries to identify the specific target schema and direct the query to that schema. The hook also identifies and rejects database queries missing the required schema identifiers. As an additional layer of protection, the hook is built to reject complex nested queries where schema references are not consistent between different subqueries.
-- A valid query
-- Event without qualifying the table name with the DB schema,
-- the query will be routed to client_12.transaction automatically
SELECT DISTINCT ticker_symbol_id FROM transaction WHERE client_id = 12;
-- Invalid query, no client attribution
SELECT * FROM transaction;
-- Invalid query, the joined table lacks client attribution
SELECT * FROM transaction
INNER JOIN position
ON transaction.position_id = position.id
WHERE
transaction.client_id = 12;Examples of valid and invalid database queries in a schema-isolated world. The application will fetch the details of the security represented by ticker_symbol_id separately.
This strict application and database-level isolation of client schemas creates a deliberate architectural boundary that prevents the execution of cross-client queries within the operational environment. To support platform-wide analytics, the anonymized data is sent and aggregated in Addepar’s Databricks data lake solution.
Into the future
Supporting nearly $9 trillion in assets requires an architecture that maximizes reliability without sacrificing agility. By strictly encapsulating client data within isolated schemas, the platform can achieve a level of operational flexibility that enables precise resource management at scale. This design effectively eliminates "noisy neighbor" contention, simplifies complex regional migrations, and unlocks powerful capabilities like instant sandboxing and granular recovery.
Ultimately, this design strategy is about sustainable growth. As the platform continues to onboard larger enterprises and navigate complex regulatory landscapes, the ability to scale storage and compute horizontally remains critical. This architectural foundation does far more than support the current workload, clearing the runway for Addepar’s continual global expansion.